Advanced RAG Techniques to improve the Performance of Generative Models
What is RAG?
RAG stands for Retrieval-Augmented Generation. It is a framework designed to improve the performance of generative models like ChatGPT by incorporating information retrieval into the generation process. The idea is to retrieve relevant documents or pieces of information from a database or a knowledge base and then use that information as context to generate more informed and accurate responses.
Retrieval-augmented generation(RAG) is a method in natural language processing (NLP) that combines retrieval techniques with generative models to enhance the quality and accuracy of generated text.
Components of RAG
- Retriever: Identifies and retrieves relevant documents or passages from a large corpus based on the input query.
- Augmented Context: The retrieved documents provide additional context that supplements the original query, enhancing the generative process.
- Generator: Uses both the input query and the augmented context to generate coherent and contextually relevant responses.

Process of RAG
The Retrieval-Augmented Generation (RAG) process involves the following steps:
- Document Collection: Collect and split documents into smaller chunks for better retrieval accuracy.
- Document Embedding: Convert each document chunk into a dense vector (embedding) using an encoder model and store these embeddings in a vector database.
- Input Query: Receive the user’s query or prompt as the input.
- Query Embedding: Encode the input query into a dense vector (query embedding) using the same or a similar model used for document embeddings.
- Retrieve Most Similar Chunks: Compare the query embedding with document embeddings to retrieve the most similar chunks from the database.
- Pass Augmented Context to LLM: Combine the retrieved document chunks with the query to create an augmented context and pass it to a large language model (LLM).
- Generate Response: The LLM uses the augmented context to generate a coherent and contextually relevant response.
- Output Response: Deliver the generated response to the user, ensuring it’s informed by the retrieved documents.

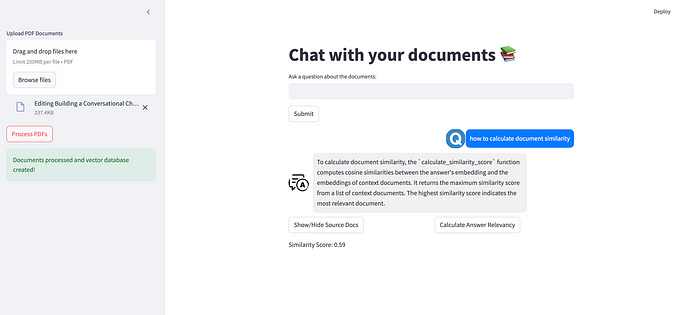
Building a RAG System — Build an Application for Chatting with Our Documents
Building a Retrieval-Augmented Generation (RAG) system to create an application for chatting with documents involves several steps, from setting up the document retrieval pipeline to integrating the generative model. Here’s a guide to help you build this system:
- Using LlamaIndex:
- Using LangChain
Simple RAG Drawbacks, Challenges, and Pitfalls
Retrieval-augmented generation(RAG) is a powerful approach that enhances generative models by grounding them in retrieved documents. However, it comes with several challenges and pitfalls that can impact its effectiveness.
- Limited Contextual Understanding: The RAG system may struggle with understanding and maintaining context across long conversations, leading to accurate responses but not entirely relevant to the ongoing discussion.
- Inconsistent Relevance and Quality of Retrieved Information: The quality and relevance of the retrieved document chunks can vary, especially if the retrieval step fails to select the most pertinent information, which can result in suboptimal responses.
- Poor Integration Between Retrieval and Generation: The interaction between the retrieval and generation components might not be seamless, causing issues where the generative model does not fully utilize the retrieved context, leading to generic or irrelevant responses.
- Inefficient Handling of Large-Scale Data: RAG systems can become computationally expensive and slow when dealing with large-scale data sets, as the retrieval process must sift through vast amounts of information to find relevant chunks.
- Lack of Robustness and Adaptability: The system may not adapt well to new or unseen queries, and its robustness could be compromised by noisy or ambiguous data, leading to incorrect or incoherent responses.
To address these challenges, Advanced RAG techniques have been developed to overcome the limitations of naive implementations. Advanced RAG systems incorporate more sophisticated methods to enhance contextual understanding, such as using hierarchical retrieval or multi-hop reasoning, which allows the model to better grasp complex queries and provide more nuanced responses.
Advanced RAG Techniques
Advanced RAG techniques introduce specific improvements to overcome the limitations of naive RAG, particularly focusing on enhancing the quality of document retrieval. These techniques employ both pre-retrieval and post-retrieval strategies to ensure that the system retrieves the most relevant and contextually appropriate documents, ultimately leading to more accurate and coherent generated responses.
1. Pre-Retrieval Enhancements
- Improved Indexing Structures: One of the key strategies in advanced RAG is the improvement of the indexing structure. By organizing the document indexes more effectively, the system can ensure that relevant information is more easily accessible during the retrieval process. This involves creating more granular indexes, using hierarchical indexing methods, or incorporating knowledge graphs that better represent the relationships between different pieces of information.
- Query Refinement: Advanced RAG also focuses on refining the user’s query before it is used for retrieval. This can include techniques like query expansion, where synonyms or related terms are added to the query, or using more sophisticated natural language processing (NLP) techniques to better understand the user’s intent. By improving the quality of the query, the system can more accurately retrieve documents that are relevant to the user’s needs.
- Data Enrichment: Another pre-retrieval strategy is data enrichment, where additional metadata or contextual information is added to the documents in the index. This can include tagging documents with relevant keywords, categorizing them by topic, or linking them to related documents. These enhancements allow the retrieval process to be more precise, as the system has more information to match against the user’s query.
2. Post-Retrieval Enhancements
- Combining Retrieved Data with the Original Query: After the initial retrieval process, advanced RAG systems often combine the retrieved data with the original user query to refine the search results further. This post-retrieval step involves re-ranking the retrieved documents based on how well they match both the original query and the additional context provided by the retrieved documents. This helps ensure that the most relevant and contextually appropriate documents are prioritized for generation.
- Contextual Re-Ranking: In some advanced systems, the retrieved documents are re-ranked based on their contextual relevance to the entire query rather than just isolated keywords. This process often involves using more advanced models, like transformer-based ranking models, that can better understand the nuances of the query and the content of the documents.
- Iterative Feedback Mechanisms: Advanced RAG systems may also incorporate iterative feedback loops where the system learns from past retrieval and generation processes. This feedback is used to adjust the retrieval algorithms and improve future performance, ensuring that the system continuously evolves to provide more accurate and relevant information.
Advanced RAG Techniques — Query Expansion with Generated Answer
Query Expansion (with Generated Answers) is a technique in Retrieval-Augmented Generation (RAG) systems that enhances the retrieval process by expanding the original user query with potential answers generated by a language model (LLM). This approach helps in obtaining more relevant context and improves the quality of the final response. The flow typically follows these steps:

1. Original Query Input: The user inputs a query into the system, which could be a question or a request for information.
2. Initial LLM Answer Generation: The system passes the original query through a large language model (LLM) to generate potential answers or additional related text. This initial step doesn’t serve as the final response but rather as a means to expand the query.
- Example: For a query like “What are the benefits of AI in healthcare?”, the LLM might generate an answer like “AI in healthcare improves diagnostic accuracy, enhances patient care, and reduces operational costs.”
3. Query Expansion: The generated answer is then used to expand the original query. This expanded query now includes not only the original terms but also the additional context provided by the LLM’s generated text.
- The expanded query might look like: “What are the benefits of AI in healthcare? AI in healthcare improves diagnostic accuracy, enhances patient care, and reduces operational costs.”
4. Vector Database Retrieval: The expanded query is then sent to a vector database, where it is used to retrieve the most relevant document chunks or context from the database. The vector database searches for documents that match both the original query and the expanded context.
- The retrieval process benefits from the expanded query because it includes more detailed and potentially relevant information, increasing the likelihood of finding the most pertinent documents.
5. Retrieval of Relevant Context: The vector database returns the top-k most relevant document chunks based on the expanded query. These chunks contain the context that best matches the expanded content, providing richer and more accurate information.
6. Final LLM Answer Generation: The retrieved document chunks, along with the original query, are passed to the LLM once more. The LLM uses this augmented context to generate a more informed and accurate final answer.
- With the additional context from the relevant documents, the LLM can generate a response that is not only contextually accurate but also more comprehensive.
7. Final Response to User: The system delivers the final, contextually enriched answer to the user. This answer is likely to be more relevant and informative than one generated from the original query alone.
This process improves contextual understanding, enhances retrieval quality, and provides more comprehensive responses.
Implementation for Advanced RAG Techniques
Your implementation of advanced Retrieval-Augmented Generation (RAG) techniques with query expansion looks robust. Here’s a breakdown of your approach and the steps involved:
1. Extract Text from PDF
- Function Definition:
def extract_text_from_pdf(file_path):
text = []
with open(file_path, "rb") as file:
pdf = PdfReader(file)
for page_num in pdf.pages:
page = page_num.extract_text().strip()
text.append(page)
return "\n".join(text)- Extract Text Using
PdfReader:
from pathlib import Path
reader = PdfReader("genai-principles.pdf")
pdf_texts = [p.extract_text().strip() for p in reader.pages]
pdf_texts = [text for text in pdf_texts if text]2. Text Splitting
- Character-Based Splitting:
from langchain.text_splitter import RecursiveCharacterTextSplitter
character_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ". ", " ", ""], chunk_size=1000, chunk_overlap=0
)
character_split_texts = character_splitter.split_text("\n\n".join(pdf_texts))- Token-Based Splitting:
from langchain.text_splitter import SentenceTransformersTokenTextSplitter
token_splitter = SentenceTransformersTokenTextSplitter(
chunk_overlap=0, tokens_per_chunk=256
)
token_split_texts = []
for text in character_split_texts:
token_split_texts += token_splitter.split_text(text)3. Chroma Vector Database Setup
- Embedding Function:
from chromadb.utils.embedding_functions import SentenceTransformerEmbeddingFunction
embedding_function = SentenceTransformerEmbeddingFunction()- Create and Populate Collection:
import chromadb
chroma_client = chromadb.Client()
chroma_collection = chroma_client.create_collection(
"gpt4-collection", embedding_function=embedding_function
)
ids = [str(i) for i in range(len(token_split_texts))]
chroma_collection.add(ids=ids, documents=token_split_texts)4. Query Processing and Expansion
- Generate Augmented Query:
import os
from openai import OpenAI
def augment_query_generated(query, model="gpt-3.5-turbo"):
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
prompt = "You are a helpful expert AI assistant. Generating professional and clear replies to CRM tickets to the given tickets."
messages = [
{"role": "system", "content": prompt},
{"role": "user", "content": query},
]
response = client.chat.completions.create(
model=model,
messages=messages,
)
return response.choices[0].message.content5. Search and Visualization
- Perform Query and Retrieve Documents:
query = "Introduction to Language models"
results = chroma_collection.query(query_texts=[query], n_results=5)
retrieved_documents = results["documents"][0]- Project Embeddings with UMAP:
import umap
import matplotlib.pyplot as plt
def project_embeddings(embeddings, umap_transform):
projected_embeddings = umap_transform.transform(embeddings)
return projected_embeddings
embeddings = chroma_collection.get(include=["embeddings"])["embeddings"]
umap_transform = umap.UMAP(random_state=0, transform_seed=0).fit(embeddings)
projected_dataset_embeddings = project_embeddings(embeddings, umap_transform)6. Plot Results
- Visualize Embeddings
plt.figure()
plt.scatter(projected_dataset_embeddings[:, 0], projected_dataset_embeddings[:, 1], s=10, color="gray")
plt.scatter(projected_retrieved_embeddings[:, 0], projected_retrieved_embeddings[:, 1], s=100, facecolors="none", edgecolors="g")
plt.scatter(projected_original_query_embedding[:, 0], projected_original_query_embedding[:, 1], s=150, marker="X", color="r")
plt.scatter(projected_augmented_query_embedding[:, 0], projected_augmented_query_embedding[:, 1], s=150, marker="X", color="orange")
plt.gca().set_aspect("equal", "datalim")
plt.title(f"{original_query}")
plt.axis("off")
plt.show()This comprehensive approach ensures that your retrieval and augmentation process is both efficient and effective, leveraging advanced RAG techniques. If you have any specific questions or need further modifications, feel free to ask!
Conclusion
Advanced Retrieval-Augmented Generation (RAG) techniques significantly enhances the quality of information retrieval and response generation. By optimizing indexing, refining queries, and enriching data, these methods address common challenges in naive RAG systems. The approach includes extracting and splitting text, generating embeddings, and expanding queries with language model-generated answers to improve document retrieval and generate more accurate responses.
These advancements ensure that users receive precise and contextually relevant answers, making the system more robust and effective. Embracing these techniques brings a new level of efficiency and accuracy to information retrieval, promising better user experiences and more reliable outcomes. For further exploration, consider reviewing resources on Langchain, ChromaDB, and UMAP to deepen your understanding and application of these methods.
Happy Learning!